Fuzzy Suggestions using Trigram Similarity
January 6, 2022 - Reading time: 8 minutes
The new Raveberry version 0.9.9 features vastly improved suggestions. Before, some substrings of a word had no suggestions, even though it was in the database. Common words (and, a, the, etc.) were ignored completely. See "Full Text Search" for an explanation. Now in these cases there are meaningful suggestions, and what's even better, the query can now contain typos and still receive suggestions. And still, the new suggestions are faster than before. This article explains how they were previously provided and how it works now, how they are more usable and how they are faster. Afterwards, there is a small summary of other changes in the new version.
Full Text Search
Before, django-watson was used to provide suggestions for a given query. This library implements search mechanisms for multiple database backends and is relatively easy to use. For SQLite3, naive regex-matching is used, without the possibility of search result ranking. SQLite3 is only used in the debug server of Raveberry, postgres is the important backend that is used in production setups. For postgres, its built-in full text search is used.
Full text search is a very fast and efficient method that can search large amounts of entries for a given query and rank them by similarity. In order to achieve high performance, postgres makes use of a number of indexes. This allows queries to run against data of a precomputed structure, decreasing the time needed for a query. An example for such precomputation is word stemming. postgres uses dictionaries to normalize words into a canonical form. "banking", "banked", "banks", "banks'", and "bank's" would all be normalized to "bank", so you can search for "banks" and still find entries containing the word "bank". However, this also means that "ban" will not find "bank", because they are not normalized to the same word. For Raveberry suggestions, this is quite unintuitive, because a substring of a word might find a song, but with one more letter it won't.
Another method to improve performance is to filter out so called stop words. These are words that appear very often and thus don't identify a possible result very well. For searching many documents with long queries this is efficient, but for small queries and short titles this makes it very hard to find some songs.
To sum up, full text search is a very powerful tool that really shines in the right applications. For Raveberry however, it is not perfectly appropriate. Some of these problems could be configured to suit this project better, but then we couldn't use django-watson. And if we start dealing with postgres configuration directly, we can choose a search method that suits Raveberry better:
Trigram Similarity
Trigram similarity is another approach to search entries for a given query, but it supports fuzzy matching. This means that the query does not need to match a result exactly, an approximate match is fine. For example, "uprsing" would still match "uprising". This is achieved by comparing trigrams, i.e. sets of three characters. "uprsing" has the trigrams [upr, prs, rsi, sin, ing], while "uprising" has the trigrams [upr, pri, isi, sin, ing]. Despite the typo, 3 trigrams are still identical and the match can be detected. The number of matching trigrams also proves to be very useful as a ranking metric, so the most similar result can be shown on top.
Performing a query with trigram similarity is significantly more expensive that full text search. This manifests in Raveberry if your instance is was active for a long time and collected a lot of possible songs to suggest from. However, the query was structured so it can make use of indexes, drastically reducing query time. It is still slower than full text search, but now only by a factor of ~4 instead of 40, making its usage feasible.
For more information you can read the documentation on full text search and trigram similarity.
Speed
The time that was lost by switching the search method was more than made up for by other improvements in the suggestion flow.
What yielded the best improvement was caching song metadata. Before, whether a song was available and its duration was queried every time the information was needed. For a suggestion, this might mean querying up to twenty files and parsing the audio file. Storing this data into the database cuts processing time of found suggestions down to a third. This does mean that the stored metadata might go out of sync with the file system, but Raveberry updates the metadata each night automatically.
Other modifications contributed to the fast speed in 0.9.9, but not as much as the metadata inclusion:
- Settings are cached. Not every suggestion queries from the database how many entries it should show.
- The suggestion endpoint does not contribute to the active user count anymore.
Together, these changes more than halved the time it takes to provide suggestions from Raveberry's database.
UI
Additionally, suggestions are much more responsive now, not only because of the faster response. Suggestions are now split into three parts:
-
The query itself (the first line). Available instantly.
-
Online suggestions from all active platforms. Unlike in previous versions, these platforms are queried in parallel.
-
Offline suggestions from the database.
Online and offline suggestions are requested simultaneously and are shown as soon as they are available. Since online suggestions are on top, there are placeholders that are replaced with the suggestions when they arrive. If no online suggestions are found, the lines show an error instead. This way the order and position of suggestions never changes, even though their content is dynamic. Few things are more frustrating than a webpage that moves the button you want to click away right from under your fingertip.
Miscellaneous Changes
-
Upgraded to Django 4.0 from Django 2.2. This was necessary due to changes in the model-interface that allow integrating trigram similarity.
-
Django 4.0 also includes context-aware
sync_to_async, finally allowing the upgrade without usability impact. Django 3 was skipped completely, since it effectively made Raveberry single-threaded. -
This upgrade means that python 3.8 is now required for Raveberry to run. Debian buster - which was the basis for Raspberry Pi OS for the last years - ships with python 3.7, so if you want to use the new version you need to upgrade to Debian bullseye.
-
Switched from
youtube-dltoyt-dlp. This active fork fixed the issue of very slow downloads. -
The Raspberry Pi's green led now shows Raveberry activity (page loads, votes and song requests).
-
Scanning for bluetooth devices and connecting to them does not show a huge error box anymore.
-
Queue control buttons are further apart, making it harder to accidentally delete the whole queue if you just want to shuffle it.
Cheers!
Raveberry now has a Discord server
December 17, 2021 - Reading time: ~1 minute
Invite Link: https://discord.gg/dy7Jxvjj9H
Sometimes, Github issues and Reddit posts just are not the right medium, so I created a Discord server for Raveberry. It can be used to receive help for problems during setup/usage and you can give suggestions for what features you would like. There is also a short summary of things I'm currently working on, which I will update along the way.
See you over there!
Using an LED Ring with Raveberry
November 28, 2021 - Reading time: 6 minutes

Raveberry is a project that makes parties more fun by allowing everybody to influence the music. With an LED ring in the transparent case of the Raspberry Pi, I tried to make it visually interesting as well. I want to share with you how the ring is connected and controlled, how I made the lights react to the music and how I modified the colors to make them a little more appealing.
Power Supply and Interface
The ring has 16 LEDs and is pretty similar to this one from Adafruit. It is powered directly from a 3v3 Pin, the Pi can handle 16 LEDs without an external power supply. This is very convenient, as it allows me to just leave the ring attached to the case. LEDs usually are powered with 5V, however this leads to problems when controlling them from a Raspberry Pi. The Pi's GPIO pins control the ring with 3.3 volts, and if the difference between power voltage and data voltage is too high, the ring cannot read the data correctly. Thus, either the data voltage needs to be raised with a level converter or the power voltage needs to be reduced. The latter can be accomplished with either a diode between the 5V pin and the ring, or connecting the ring to a pin with lower voltage. Since I like to keep the setup compact, I chose the last option which requires no additional hardware. With 3.3V, the LEDs can not shine quite as bright, but for my use case this is easily enough. You can read more about the possible wiring options in this Adafruit article.
The LEDs are controlled via the SPI interface of the Raspberry Pi. The rpi_ws281x library is used to manage the ring from python code. The library also provides the possibility to control LEDs via PWM or PCM, however this either disables either analog or digital audio output, which is quite disadvantageous for a music server. On a Raspberry Pi 4, there is one thing to look out for: SPI requires a stable clock, and the Pi 4 throttles itself by default. This can be avoided by adding core_freq_min=500 to /boot/config.txt. Raveberry takes care of this during install if you enable LED visualization.
Audio-Reactive Lighting
In the first video, you can see how the LEDs light up to the beat of the music in realtime. In order to produce this effect, multiple steps are necessary. First, mopidy (the music player) duplicates the audio output into a fake pulseaudio sink. cava then captures the audio from this sink and transforms it, splitting it into its frequencies. Raveberry maps these frequencies to colors from red to blue and lights up the LED ring accordingly. Since the transformation takes a short amount of time, the audio output is delayed by approximately that time to sync the light flashes with the beat. All in all, this allows for a pretty neat sound-reactive spectrum visualization on the LED ring.
If you feel the reactive mode is too agitated, you can also make the ring smoothly cycle through all colors in a rainbow pattern:

Color Tweaking
(Caution, math ahead)
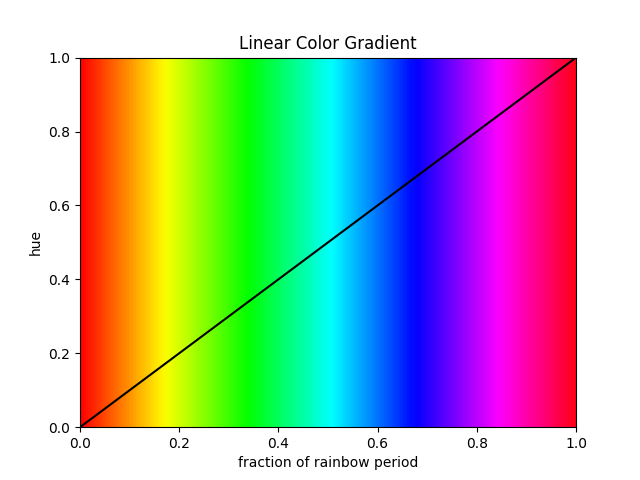
A rainbow can easily be generated with the HSV (Hue, Saturation, Value) color space. By setting saturation and value to 1 and moving the hue from 0 (red) over ⅓ (green) over ⅔ (blue) to 1 (red again), every color is produced. The result is what you see in the graph.
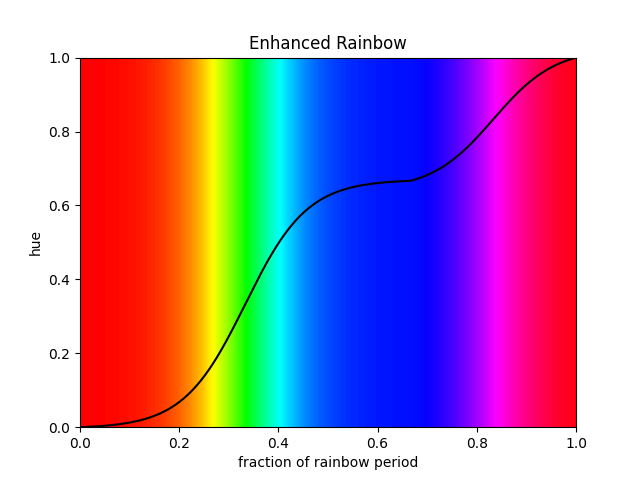
While all colors are spread equally, green is perceived to be much more prominent. This is for two reasons: First, the human eye is the most sensitive at the wavelength of green, so it looks brighter in comparison to other colors of equal intensity. Second, the board of the Raspberry Pi is green, tinting the reflected light slightly green. This is compensated by compressing green with a logistic curve and stretching red and blue. Because pink also does not look that great in the rainbow (in my opinion), it is also compressed a bit. This modified rainbow can be seen in the second video.
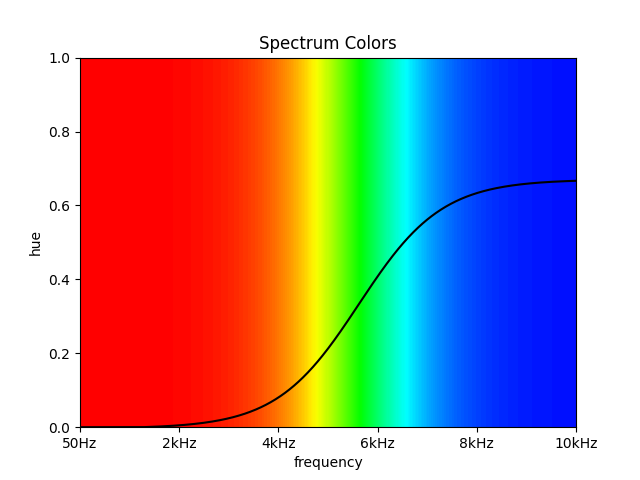
The colors used for the reactive spectrum were tweaked as well. High and low frequencies are quite different and should thus be visually separated as well. With the naive approach, both the lowest and the highest frequencies would map to red, having no visual boundary. To solve this problem, I removed pink from the spectrum completely, leading to an easily distinguishable border between red (low frequencies) and blue (high frequencies). This spectrum was also used in the audio-reactive lighting showcase.
Maybe this inspires some of you to also tinker with LEDs, putting some light to into the dark season.
0.9.5: Server Side IP Duplication Checks and Cosmetics
October 23, 2021 - Reading time: 4 minutes
The new version of Raveberry introduces a tool to make vote manipulation harder. Previously, the check whether a user is able to vote or not happened fully on the client side. Most of the time, this was not an issue. After all, people usually use this software to have fun and not to find out how to game the system. However, if someone does find out that opening a private tab is enough to vote multiple times, sometimes they exploit this knowledge. Depending on your circle of friends this may be less or more likely.
In order to maintain the spirit of Raveberry I added an option to make it a little harder for people to vote multiple times. In /settings, you can now enable "IP vote checking". If enabled, multiple votes from the same IP are not possible. IPs are not stored in the database, only in Redis. The data expires after one day, or at server restart. Of course, this approach is still not perfect, as IPs can be spoofed. However, an exploit is harder to implement and should not be found by chance from a phone. Note that if you use the discord bot, you need to keep this feature disabled. Otherwise, the bot would not be able to vote in lieu of its users.
Since I worked on IP-related stuff anyway, I decided to remove IP logging. Song requests are logged in order to provide suggestions and to allow some local analysis on the database. In order to link different requests to users, the IP address was stored along with the query. Initially, this was not really a problem, since people accessed Raveberry from a local hotspot. The IPs would only be in the local subnet and change across different usages.
However, Raveberry can also be deployed publicly, where storing IPs might be an issue. So instead of IPs, requests are now associated with the session key of a user. This key is randomly generated and carries no further information, unlike IP addresses. If you are using Raveberry like this and want to remove all IPs that were stored with earlier versions, run this command in Raveberry's directory (usually /opt/raveberry):
python manage.py shell -c 'from core.models import RequestLog; RequestLog.objects.all().update(session_key="")'If you did not yet update to the newer version, change session_key to address. If you want to keep the identifying factor you can extend the script to pseudonymize the IP.
Other than that, there were some cosmetic and other minor changes:
- The page does not scroll after clearing the input field. The problem was that browsers like to move the user to the focused element, in this case it caused erroneous scrolling however.
- After adding a new hashtag, the old one would start scrolling with a lot of whitespace added. This has been part of Raveberry since the very first mock-up and I finally came around to fix it. Opening the keyboard on mobile would resize the page, causing a scroll-recalculation while the old hashtag was invisible, leading to the weird behavior.
- The admin page in the docker image serves static files again, no more plain html. The inclusion of these files got lost during the CI migration.
/network-infoshows the correct QR code for the hotspot wifi. Before, it showed the code of the wifi the Pi was connected to twice.- Improved documentation on the remote feature in this file, adding example steps for a minimal setup.
Enjoy the new version and have a great day.
Github Actions, Discord and some more
October 3, 2021 - Reading time: 2 minutes
Version 0.9.3 was released, these are the highlights:
Raveberry uses continuous integration to run tests and publish new versions. With the last release, Raveberry moved from Travis to Github Actions. Travis recently changed their rules and tiers, granting a one-time 1000 minutes of build time. Additional time is available to non-free tiers and open source projects. However, build time for open source projects requires needs to be requested and is granted on a case by case basis. For some more information on the changes in Travis I recommend this article by the author of curl.
I took this opportunity to move the CI from Travis to Github Actions, which does not have this limitation and feels more convenient to use. Migrating required some config-tweaking, but I'm happy with the result. I also added a job that tests the system install for each version. Recently there were some issues with the installation process, these should be caught earlier now.
Additionally, the Discord bot for Raveberry is up to date again. Due to changes in Raveberry's API it was broken for quite some time, but now it works again. Maybe this could be an alternative for those seeking for a selfhosted music bot after Rhythm and Groovy were shut down.
There were some other improvements in the latest version as well:
- The database is now registered in the search plugin correctly. Previously, new songs would not show up as suggestions because the search index was not updated.
- Clearing the input field is easier, the area where the 'x' can be pressed is actually reasonable now. Previously misclicks happened regularly.
- If two suggestions are identical (e.g. two versions of the same song), the duration of the songs is shown so they can be differentiated.
- When connecting to a server for remote access, the bind address can be specified in the settings. This is helpful for docker setups on the server side.
Architecture Overhaul
July 31, 2021 - Reading time: 6 minutes
With version 0.9, Raveberry received a major overhaul of its architecture, and a bunch of other improvements.
Why the old architecture was bad
Before, Raveberry initialized itself by instantiating a single Base object, which in turn created objects related to Raveberry's different functionalities (Settings, Musiq, Lights etc.). I initially decided to use this naive object-oriented approach because responsibilities are clearly encapsulated. Each object deals with a different aspect of the project and they can communicate with each other by accessing variables or calling methods. While this makes it comfortable to design the different aspects of Raveberry and their interactions, it comes with a big drawback: Relying on a single object to handle all requests limits Raveberry to a single process.
The single object performs one-time initializations and contains locks to ensure correct behavior. Additionally, it creates background threads to control playback and compute the visualization. Creating a second instance would break all of this functionality, as for example two threads would simultaneously try to play songs. Thus, the old architecture could not be expanded beyond a single process.
Even if threads allow executing different tasks seemingly in parallel in a single process, this is not the case in Python. Due to Python's Global Interpreter Lock only one thread can execute python code at once. If most threads are IO-bound, this is not a problem, because other threads can execute during wait times. If a thread does a lot of computation though, it impacts the performance of other threads. Particularly the thread rendering the visualization at ~30fps falls into this category.
Why the new architecture is better
This architectural limitation has bothered me for a long time, and I finally came around to implement a cleaner solution. Long running tasks are now queued via Celery, where they run in separate processes, benefiting from full parallel performance. Interactions between those tasks and request handlers are coordinated through Redis and the database.
Since one task cannot simply access attributes of the respective python object anymore, I needed to revisit the interactions between the different components. For each one, I looked into which database keys, Redis values or locks it requires. This improved the general code quality, because it lead to clearly defined interfaces and reduced coupling between components.
Now, all state is kept in centralized locations (Redis, db) independent of the tasks or requests. More expensive requests (such as enqueuing new songs) are processed as celery tasks, moving out work from the main request/response cycle. This means that a single instance of daphne, the server used by Raveberry, is able to handle all incoming requests, even though now it would be possible to start a second instance.
Consequences of the change
Aside from being a cleaner implementation, this new architecture also has some practical side effects:
- Better performance due to true parallelism
- More robust, tasks can be restarted on error
- Playback starts instantly, instead of when loading the first page
A little explanation on the last point: Before, I needed a place to initialize the object. I had problems with django's ready function, as it was called for management commands as well. Thus, I put the initialization into the urls.py file, where the mappings from url to handler function are defined. This file is only parsed when the first request is made and thus the object is not initialized for management commands. It also means that playback only started when the first page loaded. With the new architecture, this is not the case anymore. You can enjoy your music as soon as the server boots up.
Other improvements
Since I needed to touch almost all of Raveberry's code during this transition, I improved some other stuff while I was at it:
- The time of the last pause is stored in the database. This allows Raveberry to calculate the progress of the current song without executing an expensive query to the player for each request. Also, restarting the server after seeking a song resumes playback at the correct position.
- Player errors are indicated by coloring the current song title red. The admin can restart the player / the server to fix this. This also (finally) prevents the rare "queue-eating" error, where Raveberry would discard the whole queue because songs can not be played.
DJANGO_MOCKandDJANGO_POSTGRESare not used anymore to tell Raveberry how to behave. It only initializes the server when called withdaphneorrunserver, management commands are possible without any environment variables.daphnelogs into its own log file instead of cluttering syslog.
Closing thoughts
I meant to do this rewrite for a long time, always postponing it due to the seemingly daunting amount of work. Now I am very happy that I can finally present this change. I want to thank r/django for their valuable input to the problem in this post. This definitely helped me make this architecture change possible.
Another factor is that recently things went back to being a little bit more normal again (at least over here), allowing for some uses of Raveberry in real life. Seeing this project in action always makes me happy and motivates me to improve it.
With this change finally implemented, I'm starting to feel confident enough to call Raveberry "stable" not too far in the future. Are there things you would like to see in Raveberry 1.0?