Fuzzy Suggestions using Trigram Similarity
January 6, 2022 - Reading time: 8 minutes
The new Raveberry version 0.9.9 features vastly improved suggestions. Before, some substrings of a word had no suggestions, even though it was in the database. Common words (and, a, the, etc.) were ignored completely. See "Full Text Search" for an explanation. Now in these cases there are meaningful suggestions, and what's even better, the query can now contain typos and still receive suggestions. And still, the new suggestions are faster than before. This article explains how they were previously provided and how it works now, how they are more usable and how they are faster. Afterwards, there is a small summary of other changes in the new version.
Full Text Search
Before, django-watson was used to provide suggestions for a given query. This library implements search mechanisms for multiple database backends and is relatively easy to use. For SQLite3, naive regex-matching is used, without the possibility of search result ranking. SQLite3 is only used in the debug server of Raveberry, postgres is the important backend that is used in production setups. For postgres, its built-in full text search is used.
Full text search is a very fast and efficient method that can search large amounts of entries for a given query and rank them by similarity. In order to achieve high performance, postgres makes use of a number of indexes. This allows queries to run against data of a precomputed structure, decreasing the time needed for a query. An example for such precomputation is word stemming. postgres uses dictionaries to normalize words into a canonical form. "banking", "banked", "banks", "banks'", and "bank's" would all be normalized to "bank", so you can search for "banks" and still find entries containing the word "bank". However, this also means that "ban" will not find "bank", because they are not normalized to the same word. For Raveberry suggestions, this is quite unintuitive, because a substring of a word might find a song, but with one more letter it won't.
Another method to improve performance is to filter out so called stop words. These are words that appear very often and thus don't identify a possible result very well. For searching many documents with long queries this is efficient, but for small queries and short titles this makes it very hard to find some songs.
To sum up, full text search is a very powerful tool that really shines in the right applications. For Raveberry however, it is not perfectly appropriate. Some of these problems could be configured to suit this project better, but then we couldn't use django-watson. And if we start dealing with postgres configuration directly, we can choose a search method that suits Raveberry better:
Trigram Similarity
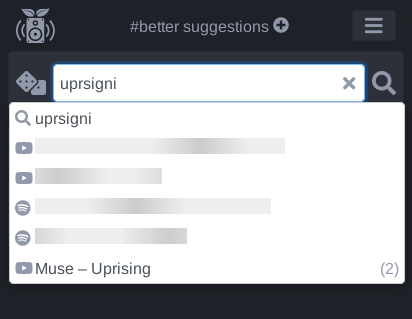
Trigram similarity is another approach to search entries for a given query, but it supports fuzzy matching. This means that the query does not need to match a result exactly, an approximate match is fine. For example, "uprsing" would still match "uprising". This is achieved by comparing trigrams, i.e. sets of three characters. "uprsing" has the trigrams [upr, prs, rsi, sin, ing], while "uprising" has the trigrams [upr, pri, isi, sin, ing]. Despite the typo, 3 trigrams are still identical and the match can be detected. The number of matching trigrams also proves to be very useful as a ranking metric, so the most similar result can be shown on top.
Performing a query with trigram similarity is significantly more expensive that full text search. This manifests in Raveberry if your instance is was active for a long time and collected a lot of possible songs to suggest from. However, the query was structured so it can make use of indexes, drastically reducing query time. It is still slower than full text search, but now only by a factor of ~4 instead of 40, making its usage feasible.
For more information you can read the documentation on full text search and trigram similarity.
Speed
The time that was lost by switching the search method was more than made up for by other improvements in the suggestion flow.
What yielded the best improvement was caching song metadata. Before, whether a song was available and its duration was queried every time the information was needed. For a suggestion, this might mean querying up to twenty files and parsing the audio file. Storing this data into the database cuts processing time of found suggestions down to a third. This does mean that the stored metadata might go out of sync with the file system, but Raveberry updates the metadata each night automatically.
Other modifications contributed to the fast speed in 0.9.9, but not as much as the metadata inclusion:
- Settings are cached. Not every suggestion queries from the database how many entries it should show.
- The suggestion endpoint does not contribute to the active user count anymore.
Together, these changes more than halved the time it takes to provide suggestions from Raveberry's database.
UI
Additionally, suggestions are much more responsive now, not only because of the faster response. Suggestions are now split into three parts:
-
The query itself (the first line). Available instantly.
-
Online suggestions from all active platforms. Unlike in previous versions, these platforms are queried in parallel.
-
Offline suggestions from the database.
Online and offline suggestions are requested simultaneously and are shown as soon as they are available. Since online suggestions are on top, there are placeholders that are replaced with the suggestions when they arrive. If no online suggestions are found, the lines show an error instead. This way the order and position of suggestions never changes, even though their content is dynamic. Few things are more frustrating than a webpage that moves the button you want to click away right from under your fingertip.
Miscellaneous Changes
-
Upgraded to Django 4.0 from Django 2.2. This was necessary due to changes in the model-interface that allow integrating trigram similarity.
-
Django 4.0 also includes context-aware
sync_to_async, finally allowing the upgrade without usability impact. Django 3 was skipped completely, since it effectively made Raveberry single-threaded. -
This upgrade means that python 3.8 is now required for Raveberry to run. Debian buster - which was the basis for Raspberry Pi OS for the last years - ships with python 3.7, so if you want to use the new version you need to upgrade to Debian bullseye.
-
Switched from
youtube-dltoyt-dlp. This active fork fixed the issue of very slow downloads. -
The Raspberry Pi's green led now shows Raveberry activity (page loads, votes and song requests).
-
Scanning for bluetooth devices and connecting to them does not show a huge error box anymore.
-
Queue control buttons are further apart, making it harder to accidentally delete the whole queue if you just want to shuffle it.
Cheers!